BBC News – a new Widget for Android
Posted by jimblackler on Jul 3, 2009
Update
28th May 2011: BBC News is now UK & World News. Two years on, two million downloads later, same app, new name. I hope you all continue to enjoy reading the BBC News site through my app.
Original article
 BBC News is a widget for Android for that shows you the latest news headlines in a compact 2 x 1 widget on the Android home screen. Clicking on the widget takes you to a full list of headlines and more story details.
BBC News is a widget for Android for that shows you the latest news headlines in a compact 2 x 1 widget on the Android home screen. Clicking on the widget takes you to a full list of headlines and more story details.
In the headline view, clicking on a headline will in turn take you to the mobile version of the BBC News page on your Android browser.
Feed selection
Each widget can be customised to show content from any of the BBC’s feeds. The default is the Most Popular feed, but users can choose others such as Sports headlines, Entertainment or Technology news.

Android users outside the UK will see the international versions of feeds and stories. UK users will see the local version by default, although any user can switch between UK and international versions in the Preferences.
You can have multiple widgets on your home screen. They will not normally show the same story, so if you set up three widgets from the same feed you will have the first, second and third headlines shown, in the order the widgets were added.
This isn’t a general purpose feed reader. It is customised to the style of the excellent BBC News feeds to give the best experience. I saw some RSS widgets but they try to include too much text on the widget, and the result is hard to read. Also they did not use the thumbnails that accompany each story, losing the visual appeal that they add.
Download
Download BBC News from the Android market now.
Credits
This program is free software under the Apache license. Supported by BBC Backstage.
I hope you enjoy BBC News. As always, leave bugs and requests here. Even if you just enjoyed the app and would like to let me know. I read all comments but I have only around an hour a day for development so I usually can’t fulfil requests. I normally act when several people start asking for the same thing.

Events Clock: A Google Calendar Visualisation with iGoogle capability. Written in ActionScript (Flash), Java (Google App Engine) and JavaScript
Posted by jimblackler on Apr 26, 2009
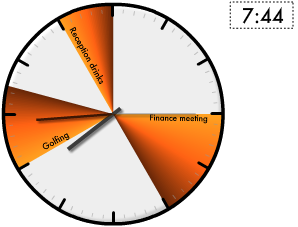
Events Clock is an experimental visualisation for your Google Calendar. It shows your upcoming events as coloured slices around a traditional clock face.
The visualisation shows where the hour hand on the clock will be when each event is in progress. The calendars shhown will match the your existing selection of visible Google Calendars. The colours are taken from the colour you have selected for each Google Calendar, with the exception of events in the past, which are shown in grey.
If there is any doubt as to where the 12 hour period begins and ends, a dotted line is shown. Clicking on the events will send you to the page on google.com/calendar for that event.
Links
To view Events Clock as a stand alone web page, click here. If you don’t use Google Calendar, or don’t have any events in your calendar over the next ten hours or so, click here for a demo.
To add Events Clock as a gadget on your iGoogle page, click here.

Concept
The idea came from the desire to see at a glance what I was supposed to be doing over the course of the day. The original idea was for a mobile phone application. However, once I’d developed a Flash prototype, I discovered iGoogle Gadgets, and the two seemed an ideal fit. I adapted the visual design for the smaller area and it seemed to work well.
As an iGoogle gadget, you’ll see an instant pictorial representation of your day’s events whenever you navigate to your Google homepage.

Accessing Google Calendar data
Events Clock uses a method called AuthSub. This enables it to get access to your Google Calendar data, with no possibility of access to anything else from your Google account. When you click to grant access, a new browser window is opened pointing at a page on Google.com. Here you can allow access to Events Clock. If you have to enter any passwords you are informing Google.com. My site will never see this information. It can’t even see your user name, or email address. All it gets is a token from Google that allows it access to your calendar data. This token is stored, encrypted, as a cookie in your browser.
Note that the Google authorisation screen warns that Events Clock has not been configured for secure access. I have in fact developed secured access, but a possible bug in App Engine appears to be blocking the secure authorisation requests.
App Engine
I used Google’s new cloud computing platform App Engine to host Events Clock. This is possible now that App Engine supports Java. This allows my app to benefit from the scalable, and of course free, hosting. The development went reasonably smoothly, although there were some teething problems with the Google Data access.
Feedback
Events Clock is a concept application, so I’d be very interested to hear your feedback, or reports of technical issues. Please leave comments on here on this blog.
BBC Listings viewer for Android
Posted by jimblackler on Feb 19, 2009

For Android phone owners in the UK, BBC Listings is a viewer and search assistant for the BBC’s TV and Radio schedules.
Users select from a list of channels, then view the schedules for that channel, one day at a time. Clicking on a program shows you a synopsis, and allows you to add a reminder to your Google calendar. Sky+ users can set their Sky+ boxes to record BBC TV programs by a text message.
(This message is prepared by the application and sent from the phone, but requires the phone to be registered for the Remote Record service with Sky. Refer to the Sky website for how to register, and costs and limitations of the Sky+ text message Remote Record service.)

Limitations
Because it gets its data from the BBC’s web services, internet access is required. Currently, one week’s worth of future listings and one week’s worth of past listings are available.
To search the listings press Menu and Search. Results are returned sorted by channel and then by date.
Download
Look for the application in the Android market (requires a UK registered mobile) or download it directly here
License
This application is free software. Supported by backstage.bbc.co.uk
History

0.9.1 : The first published version.
Feedback
If you have any comments or queries about this application, please leave them on this blog.
QuickCalendar, an application for Android written in Java
Posted by jimblackler on Jan 30, 2009
I’ve just released a simple utility QuickCalendar onto the Android Marketplace.
It’s a simple application that displays the current and the next (or the next two) events on the notification bar of your Android phone.
I wrote it because I miss a similar feature from my last phone, a Windows Mobile device. The trickiest part was getting access to the calendar data. There is a provider for calendar data, but unlike the contacts provider it is not part of the standard SDK. However the functionality can be obtained if you get the source (Android is open source), adjust the exported items and build your own SDK.
I may write an article on how to do this if there is demand. Also I will release the source for the application when I have OKed it with my employer. In the meantime you can use the application yourself by going to the Android Marketplace on your phone and searching for QuickCalendar.
Downloading
Get it from the Market, or here
Update
![]()
I’ve had some nice comments and feature requests (always welcome). As a result I’ve fixed some bugs and added some features.
- 0.9.29:
Search button supported on devices that have a hardware search button.
Corporate Calendar supported on Motorola handets.
Widgets refresh immediately when calendar is modified, when preferences are modified, and when the screen is enabled.
Progress indicator for main page.
Widgets to not refresh when screen is off, to save battery.
Refresh rate can be configured in preference screen.
Bug fixed with widget font size. - 0.9.18 : Cupcake version! Gadget for home page available. Colored indicators in task bar. Also: German language support.
- 0.9.17 : Bug fix release (service not starting on phone power up since 0.9.13).
- 0.9.16 : 24hr (aka military time) format not used in category view unless is on in phone preferences.
- 0.9.15 : Bug fix release (preference changes not taking effect).
- 0.9.14 : Context menu selection for time events. Day group headings correct in all time zones.
- 0.9.13 : Now possible to specify any time (up to 999 weeks) to look ahead for notifications and for the main event list. You are not limited to the pre-set durations. New notification icons more in keeping with the Android conventions. New choice of event list format of ‘grouped by day’ or the original classic layout. Events can be shown colored by the calendar color.
- 0.9.12 : Fixed bug introduced in 0.9.11 (time zones didn’t work). Sorry everyone. Daylight savings time should also work properly now though.
- 0.9.11 : Improved progress indicator. Attempted bug fix on calendar preference screen.
- 0.9.10 : Search option – now possible to search calendars! Minor cosmetic improvements.
- 0.9.9 : New icon from Darrel Austin. Another ‘all day’ event fix. Fixed problem with apk size.
- 0.9.8 : All day events sort correctly in all time zones. All day events future day names correct.
- 0.9.7 : Up two four alerts. All day events work in all time zones.
- 0.9.6 : aDogTrack support. Notification icons can be enabled in preferences.
- 0.9.5 : Less obtrusive notify icons. Start service on power on option.
- 0.9.4 : Ability to select/deselect calendars to alert (where you have multiple calendars).
- 0.9.3 : Fixed problem where the notifications stopped updating.
- 0.9.2 : Fixed problem where the time zone was ignored.
- 0.9.1 : The first published version.